If at first you don't succeed ... then try, try and try again said my primary school headmistress. Today's primary school teacher would probably say something different, like if at first you don't succeed fail fast and pivot.
Facetious ramblings aside, I have been thinking a lot abut persistence recently. I mean in the sense of data storage that survives a crash or the power being turned off.
I thought I would write some stuff down.
1) I have heard about SQL and NoSQL, what is that? A short, opinionated guide for the perplexed.
2) Persistence and Constancy. Or the need to be prepared to switch persistence solutions and some thoughts about how to lessen the pain.
3) ORMs, a Faustian Pact. A rather detailed discussion. Of interest to engineers, if anyone.
Hope of some use
Jo
Sunday 26 April 2015
SQL and NoSQL: What's the difference, why would I care?
Most of us need to store data as part of our products. At small scale and low volumes this isn't all that problematic, and at the proof of concept and early trial stage one technology choice is possibly pretty much the same as another.
As things scale out the technology choice becomes more important. When it comes to storage (or persistence, more accurately, if we mean the stored data survives loss of power) there are a couple of choices. Lots of people will have heard of SQL and NoSQL.
As a business person, ideally you should actually not have to care. In this post there are a couple of tips for you to think about when your engineering team burbles excitedly about the wonders of Mongo, the cruftiness of MySQL, the thrill of the new ... OK, you'd prefer not to care.
Before getting on to the tips, here is a brief and somewhat incorrect guide to the technology (never mind, it's brief).
What is SQL?
SQL is actually a language for accessing storage rather than a storage technology itself, the storage technology being Relational Database Management System or RDBMS for short. This technology has been around since the dawn of time (the early 1970s) and so has the advantage of being extremely mature.
SQL databases can usually be configured with a high degree of fault tolerance and offer strong guarantees about the integrity of data. For example, if a bank receives two requests to debit £10 from an account containing £15 only one can succeed. SQL databases support transactions that have so-called "ACID" properties - which NoSQL databases usually lack to some degree or other.
Unsurprisingly, given they do so much, SQL systems can be rather big, cumbersome and have a reputation for being quite inflexible.
MySQL is a well-known example of a SQL system in use among smaller companies. PostgreSQL seems to remain a choice for some too. Larger companies may use Oracle (which also owns MySQL) and Microsoft SQL Server.
NoSQL
NoSQL is possibly not a brilliant term for the extremely wide variety of non-relational storage mechanisms, the term having been popularised around 6 or 7 years ago, possibly because SQL was not used as a data access language at that time.
There was and is an increasingly bewildering variety of technologies that fall under this label, which may have little in common with each other and each of which had the purpose of addressing perceived shortcomings of or over-engineering of the traditional relational approach. Today some NoSQL databases actually do provide SQL access to data, making the term even less pertinent.
Some common NoSQL choices are:
Redis: A blindingly fast key/value store. "In the case of a complete system failure on default settings, only a few seconds of data would be lost." Often used for caching - i.e. it's not the reference data store for anything and if it crashes can be easily rebuilt without loss of business data. Given the above quote, though, probably not the place to store financial transactions on the default settings.
MongoDB: A document database, grand daddy of them all in some ways. Possibly showing signs of its age a bit, though the new version 3.0 is promoted as being really quite shiny. Lots of people love it, and it has many detractors too. You have to configure Mongo very carefully to be sure that you are not open to data loss in some failure scenarios.
Others: Couchbase, Cassandra, Riak, Aerospike ... oh goodness, the list goes on. All with pros and cons.
How to Choose
Choosing which technologies to use where is quite hard and requires quite a lot of thought. Despite the inconvenience of using more than one technology to do what is ostensibly "the same thing", this is actually a respectable engineering choice and is probably "current best practice".
It's inconvenient to use more than one technology because your engineering staff need to know what to use and when. The operations aspect becomes quite a lot more complex, since performance tuning, resilience and backup strategies need to be thought about separately for each of the different technologies you deploy.
Roughly speaking two different technologies means twice the operational burden and cost, and diagnosis of problems becomes correspondingly more complex and if there are more things that can break, well, more things will break.
Nonetheless, cost/performance trade off may still make a heterogeneous persistence choice sensible.
Conclusions
So what's the answer?
For a while people would think If it's about persistence stick it in MySQL. Nowadays that's changed to If it's about persistence that means stick it in Mongo.
If you are still at the prototype or early trial stage and if I'm talking to you over at Wayra, I won't bat an eyelid almost no matter what you're using. It probably won't scale. You're probably going to rewrite everything you have before this becomes an issue. Concentrate on getting the functionality right and as far as persistence is concerned, well, if you can bear loss of data it doesn't much matter.
If you're doing a finance or banking solution, or something like that, it really does matter, no matter what stage you are at. Read on. Likewise if you're at a later stage then you need to be more careful about considering if the technology is appropriate to your use case.
For a while people would think If it's about persistence stick it in MySQL. Nowadays that's changed to If it's about persistence that means stick it in Mongo.
If you are still at the prototype or early trial stage and if I'm talking to you over at Wayra, I won't bat an eyelid almost no matter what you're using. It probably won't scale. You're probably going to rewrite everything you have before this becomes an issue. Concentrate on getting the functionality right and as far as persistence is concerned, well, if you can bear loss of data it doesn't much matter.
If you're doing a finance or banking solution, or something like that, it really does matter, no matter what stage you are at. Read on. Likewise if you're at a later stage then you need to be more careful about considering if the technology is appropriate to your use case.
- Don't reject SQL/Relational persistence because it's old and out of date. It's mature and battle hardened and does stuff that other technologies just don't.
- Over the years many management reporting tools have been written that interface with SQL systems. Theoretically, at least, they allow non technologists to get reports on their data without having to take engineering time to do this. That is a significant advantage and says that if you're using a system that has SQL access you will hopefully be able to use these tools.
- If the above is not an issue and if you don't need strong transactional guarantees or you don't need to recover to "point in time" in the event of a failure then key value stores can be blindingly fast and may suit your needs just as well or indeed much better than an RDBMS.
- Read the documentation carefully, and test in a simulated environment. You can't possibly tell whether a persistence solution is good for you until you've thought carefully about the fit for your data and tried it out.
- Despite increased operational complexity, mix and match may be a good compromise for your applications.
- Make sure your data is duplicated reliably. In Mongo that means the write concern is Majority. That's not the default.
- NoSQL can appear to offer liberation from having to think carefully about your data structures up front as it it offers the seeming possibility of saying "it doesn't matter, we can change it easily". Really don't do that.
- Be very, very careful about concurrency. For example, simple actions like "create or update" are prone to disastrous consequences, if you don't guard against near simultaneous duplicate requests. This is much harder and more subtle than it seems at first glance. Almost everyone has this problem and it's rarely dealt with properly.
- Don't wear a MongoDB T-Shirt at Wayra London on Wednesdays, because if I see you wearing one I'll be resisting a temptation to punch you, based on recent experience of performance testing it. Not those of you who are bigger than me, obvs.
Hope the above helps.
Jo
Jo
Persistence and Constancy: How to store your data permanently but change your storage solution
Your requirements are simple: you want to store data safely, you don't want to be tied to a particular vendor or technology.
I can't remember a time at which thinking and available products have been moving faster and where it has been more difficult to formulate tactics - let alone strategy. But there are some general themes.
Having a three node MongoDB cluster and a two node MySQL and duplicated Redis is obviously overkill for a small deployment, isn't it?
Someone said to me recently that it has become true that best current practice is to have more than one type of technology for persistence. I have to reluctantly agree, irrespective of trying to keep your deployment minimal, as above.
A good example is the arrival of MongoDB's Wired Tiger storage engine, in MongoDB 3.0. In my tests it's slower, not - as advertised - much faster. How can this be? My results are not consistent with other benchmarks, even from those with an axe to grind (e.g. Couchbase).
Perhaps it's because I tested it on slow rotating disks and it's designed for SSDs. Perhaps it's because it's not suitable for the workload we have. Perhaps that's why MongoDB now maintains two storage engines. Perhaps it really is just slower at the moment. That's a lot of "Perhaps's". In any case it does not appear to be the answer to this particular MongoDB maiden's prayer and I just have to focus my efforts on functional application enhancements, not delving around in the innards of the persistence engine that I have chosen.
In the same tests the TokuMX storage engine was much (5x) faster. But it looks like it's at Mongo 2.4 and was provided by a small and relatively unknown company. That's changed, since Tokutek was acquired by Percona and presumably this may help accelerate Tokutek's plan to make it a third storage engine choice in Mongo 3.0.
You can't choose your technologies off the spec sheet or by hearsay, you have to try them. As a small company, you may not have resources to try them properly and by the time you discover their limitations you are committed. Because of time and money constraints you need to stick with it and try to make it work out. Hopefully your technology vendor is moving fast and fixes and enhancements arrive in time ...
Another reason for change is that you find out something you really don't want to hear. My thanks (I suppose!) to Nick Reffitt, CTO over at Tapdaq for bringing this article about flaws in MongoDB to my attention. It's a very good but very long article, not for the faint hearted, which in brief asserts that Mongo has some failure modes that mean you will lose data or that the data you retrieve will not be consistent. Even if I'd been sublimely happy with MongDB before, I'm not now. A chat with my CEO is due. Cough, Hi Dan ...
It's also possible that something new will come along which appears to have features that are a better fit for what you're doing. This one is harder to explain to your CEO. Really practice in front of a mirror. Try smiling. Try to make sure that a change of this kind has measurable bottom line benefits.
Either way, how can you best be prepared for change that in some time frame is inevitable? There will be pain and anguish. Data migration is not fun. How can you minimise the disruption?
There are textbook, or accepted answers. If you haven't separated your storage concerns into a service layer and a DAO layer, people will sneer at you and if your domain objects don't have nice ORM annotations, well, people are going to say that your code doesn't smell good, so don't go out to any parties till you fix that.
Even so, at risk of a spot of sneering, let's challenge accepted wisdom. I'm not saying don't use these accepted techniques, just be aware that they may not be doing for you what you were hoping.
ORMs: A Faustian Pact goes into that in more detail.
Jo
Oh, one more thought: in general, if your framework locks you into a single persistence solution, think again whether you should be using it. Specifically, Meteor users, I mean you.
I can't remember a time at which thinking and available products have been moving faster and where it has been more difficult to formulate tactics - let alone strategy. But there are some general themes.
Keep your Deployment Minimal
The more technology you have the harder your operations are. You have to know a lot about each additional piece of technology. The more instances you use to run your technology the more costly it is. Long and short is that it's desirable to minimise your dependencies.Having a three node MongoDB cluster and a two node MySQL and duplicated Redis is obviously overkill for a small deployment, isn't it?
Horses for Courses
In the world of persistence, like everywhere else, different technologies are good at different things. Some technologies are very poor at some things but good at others. If your requirement spans a range of functions then you're going to find that you need more than one type of technology.Someone said to me recently that it has become true that best current practice is to have more than one type of technology for persistence. I have to reluctantly agree, irrespective of trying to keep your deployment minimal, as above.
Choosing Technology is Hard
There are many choices. Much of the information is vague and much of the discussion around is misleading or wrong. The only practical choice for a small engineering team is to narrow down the choices and try them one by one. Of course, while you are doing that everyone is busy upgrading their technology.A good example is the arrival of MongoDB's Wired Tiger storage engine, in MongoDB 3.0. In my tests it's slower, not - as advertised - much faster. How can this be? My results are not consistent with other benchmarks, even from those with an axe to grind (e.g. Couchbase).
Perhaps it's because I tested it on slow rotating disks and it's designed for SSDs. Perhaps it's because it's not suitable for the workload we have. Perhaps that's why MongoDB now maintains two storage engines. Perhaps it really is just slower at the moment. That's a lot of "Perhaps's". In any case it does not appear to be the answer to this particular MongoDB maiden's prayer and I just have to focus my efforts on functional application enhancements, not delving around in the innards of the persistence engine that I have chosen.
In the same tests the TokuMX storage engine was much (5x) faster. But it looks like it's at Mongo 2.4 and was provided by a small and relatively unknown company. That's changed, since Tokutek was acquired by Percona and presumably this may help accelerate Tokutek's plan to make it a third storage engine choice in Mongo 3.0.
You can't choose your technologies off the spec sheet or by hearsay, you have to try them. As a small company, you may not have resources to try them properly and by the time you discover their limitations you are committed. Because of time and money constraints you need to stick with it and try to make it work out. Hopefully your technology vendor is moving fast and fixes and enhancements arrive in time ...
When it Comes to Change
It's foreseeable that despite your constancy your solution doesn't grow with you. It's impossible for you to foresee this unless you have done more testing than you probably have time to do. You have to take a punt, there's a good chance you will lose. You're going to tell your CEO that they are not going to get new features they need for sales and that you're going to have to replace something with no functional gain. I recommend that you practice the argument in front of a mirror before trying it in the office.Another reason for change is that you find out something you really don't want to hear. My thanks (I suppose!) to Nick Reffitt, CTO over at Tapdaq for bringing this article about flaws in MongoDB to my attention. It's a very good but very long article, not for the faint hearted, which in brief asserts that Mongo has some failure modes that mean you will lose data or that the data you retrieve will not be consistent. Even if I'd been sublimely happy with MongDB before, I'm not now. A chat with my CEO is due. Cough, Hi Dan ...
It's also possible that something new will come along which appears to have features that are a better fit for what you're doing. This one is harder to explain to your CEO. Really practice in front of a mirror. Try smiling. Try to make sure that a change of this kind has measurable bottom line benefits.
Either way, how can you best be prepared for change that in some time frame is inevitable? There will be pain and anguish. Data migration is not fun. How can you minimise the disruption?
There are textbook, or accepted answers. If you haven't separated your storage concerns into a service layer and a DAO layer, people will sneer at you and if your domain objects don't have nice ORM annotations, well, people are going to say that your code doesn't smell good, so don't go out to any parties till you fix that.
Even so, at risk of a spot of sneering, let's challenge accepted wisdom. I'm not saying don't use these accepted techniques, just be aware that they may not be doing for you what you were hoping.
ORMs: A Faustian Pact goes into that in more detail.
Conclusions
In the end there are no good off-the-shelf answers other than to quite simple questions. Try it, stick with it if you can, move on if you can't. Try to reduce your dependencies so moving on is less painful that it might be.Jo
Oh, one more thought: in general, if your framework locks you into a single persistence solution, think again whether you should be using it. Specifically, Meteor users, I mean you.
ORMs: A Faustian Pact
This post is a deep dive on one of the topics that I mention in Persistence and Constancy.
The discussion is about a) abstraction of persistence technology b) the practicality of switching storage solutions c) schemas and d) choosing NoSQL or RDBMS.
The separation of concerns into service, DAO and domain objects is sensible and is good practice but how much is it going to help you with the above?
OK, you're not using a strongly typed language so you don't care. I'm sorry, your get out of jail free card doesn't work. Typically a domain object refers to other domain objects by id. It doesn't matter what these "foreign keys" are stored as, they are particular to the storage mechanism you are using. i.e. if you want to migrate your storage the best these references can become are secondary index fields, if the actual id in a different type of storage is now different.
Never mind, you can always rewrite those fields during data migration. Hmmm, yes you can. Sounds tricky and error prone.
Bear in mind, also, that a standard annotation mechanism of necessity is a least common denominator solution. That means that you're not exploiting the best features of the underlying persistence mechanism. The ones that make that solution stand out from the crowd. Hmmm, that is not altogether clever. This point is made very cogently by Ronen from Aerospike in the video linked below.
And of course, the annotations that you use may not be applicable to a solution that you choose. Imagine that you're using MongoDB and that you've chosen to use Morphia. Not a bad choice at all. The problem is, of course, that when you decide to change the underlying persistence mechanism, you won't find an ORM that supports Morphia annotations. So you have to re-annotate.
During migration you're most likely going to have two sets of annotations on the same domain objects. Never mind, it's a bit ugly, but it can be made to work, given of course that the fields of the domain objects are not either strongly or implicitly typed to underlying persistence data types. Remember that whereas the underlying type is explicit in strongly types languages, things do still have a data type whatever language you are using, and even if you're storing an id as a string it's still an id that is closely coupled with the underlying storage.
Now, if you find that all your domain objects are entities, well, that means you have nicely normalised all your data. That's good practice, right? And you're using an RDBMS, right? You're not? You're using MongoDB? Really? Why?
If your domain objects are basically a projection of an RDBMS schema then why aren't you using an RDBMS? Using a non-relational store is potentially the worst of both worlds. If your domain objects are basically structured according to a schema then you can get the benefit of joins and all the tremendously useful things that RDBMS does and that NoSQL doesn't. What's more you are not taking advantage of the basically schema free-nature of NoSQL, and schema changes are going to have similar impact as a result of your domain object and ORM choices as if your persistence was RDBMS based, and that's why you chose NoSQL in the first place, probably?
It is true that, for example, MongoDB provides for queries by field missing or not. And that helps with schema upgrades, because your DAOs can use this information and be flexible. But you need to be careful. I mean very careful, you're not careless about your data, I'm sure.
Plus it may not work. If you're using MongoDB you're probably aware that in place updates are quicker than updates that extend a record (document) beyond the current storage size. Consequently it may be important for performance reasons to pre-populate your records to their expected maximum size, so that they don't move on disk and require allocation to take place on an update. I probably don't need to point out that this negates any possibility of using "field not present" techniques.
The discussion is about a) abstraction of persistence technology b) the practicality of switching storage solutions c) schemas and d) choosing NoSQL or RDBMS.
The separation of concerns into service, DAO and domain objects is sensible and is good practice but how much is it going to help you with the above?
How Decoupled are your Domain Objects?
First of all, look at the data types of the fields of your domain objects. And in particular look at the id field. If you're using Mongo this is an ObjectId. Bzzz. Error, this is a layer violation. Your domain objects which you hoped were independent of the underlying storage now are not. This is not a domain object any more, it's a Mongo object.OK, you're not using a strongly typed language so you don't care. I'm sorry, your get out of jail free card doesn't work. Typically a domain object refers to other domain objects by id. It doesn't matter what these "foreign keys" are stored as, they are particular to the storage mechanism you are using. i.e. if you want to migrate your storage the best these references can become are secondary index fields, if the actual id in a different type of storage is now different.
Never mind, you can always rewrite those fields during data migration. Hmmm, yes you can. Sounds tricky and error prone.
Annotations or @Mephistopheles
There are standard annotations. JPA and JDO are both standard, if you are using Java. However, if you are using e.g. Hibernate then you're probably going to want to use some of its proprietary features and extensions. That's OK as long as you don't mind being locked into Hibernate. Hibernate supports lots of things, after all. Cross fingers it will support what you want to use next.Bear in mind, also, that a standard annotation mechanism of necessity is a least common denominator solution. That means that you're not exploiting the best features of the underlying persistence mechanism. The ones that make that solution stand out from the crowd. Hmmm, that is not altogether clever. This point is made very cogently by Ronen from Aerospike in the video linked below.
And of course, the annotations that you use may not be applicable to a solution that you choose. Imagine that you're using MongoDB and that you've chosen to use Morphia. Not a bad choice at all. The problem is, of course, that when you decide to change the underlying persistence mechanism, you won't find an ORM that supports Morphia annotations. So you have to re-annotate.
During migration you're most likely going to have two sets of annotations on the same domain objects. Never mind, it's a bit ugly, but it can be made to work, given of course that the fields of the domain objects are not either strongly or implicitly typed to underlying persistence data types. Remember that whereas the underlying type is explicit in strongly types languages, things do still have a data type whatever language you are using, and even if you're storing an id as a string it's still an id that is closely coupled with the underlying storage.
A Schema is a Schema is a Schema
Your domain objects are probably, in JPA terms, "entities", i.e. they are rows of a table. They probably refer to other entities by id. We talked about that above.Now, if you find that all your domain objects are entities, well, that means you have nicely normalised all your data. That's good practice, right? And you're using an RDBMS, right? You're not? You're using MongoDB? Really? Why?
If your domain objects are basically a projection of an RDBMS schema then why aren't you using an RDBMS? Using a non-relational store is potentially the worst of both worlds. If your domain objects are basically structured according to a schema then you can get the benefit of joins and all the tremendously useful things that RDBMS does and that NoSQL doesn't. What's more you are not taking advantage of the basically schema free-nature of NoSQL, and schema changes are going to have similar impact as a result of your domain object and ORM choices as if your persistence was RDBMS based, and that's why you chose NoSQL in the first place, probably?
It is true that, for example, MongoDB provides for queries by field missing or not. And that helps with schema upgrades, because your DAOs can use this information and be flexible. But you need to be careful. I mean very careful, you're not careless about your data, I'm sure.
Plus it may not work. If you're using MongoDB you're probably aware that in place updates are quicker than updates that extend a record (document) beyond the current storage size. Consequently it may be important for performance reasons to pre-populate your records to their expected maximum size, so that they don't move on disk and require allocation to take place on an update. I probably don't need to point out that this negates any possibility of using "field not present" techniques.
More Hate for ORMs
That ORM is lying to you is really long and quite definitely for geeks. But this guy, Ronen Botzer from Aerospike, really really knows his stuff. As I say, at 1hr 20min is not a light confection, so something to watch while your significant other is watching reruns of Star Wars or Sex in the City or whatever it is that your tastes diverge on. He makes some tremendously interesting points, not least of which is that Aerospike is Open Source, i.e. no FoundationDB disappointments.Take Outs
It is, in short, hard. Very hard. Think about the following:- You are not going to get away from the fact that your persistence solution can't just be swapped out. It's going to be painful.
- Just because you're using schema-free storage doesn't mean that you don't in practice have a schema. All the vendors say you need to do careful up-font thinking about your data. Don't skip that step.
- Don't normalise your data for the sake of normalising it. Economy of storage is not usually a concern that trumps performance and flexibility.
- Don't think that because you have services, DAOs and domain objects nicely separated that you're independent of underlying storage. You're not. And worse still you may not be using its best features.
- If you need joins use an RDBMS.
- Choose open source to avoid FoundationDB style disappointments.
- Always question accepted wisdom.
- Always ignore fashion.
- Never ignore hygiene.
Happy persisting
Jo
Jo
Tuesday 14 April 2015
Some thoughts on Software Development: Stack Overflow, Maslow, Trello and The Joel Test
Think of the following as "Amuse-bouches" or Canapés (why don't we have words in English for this) i.e. rather than something specifically actionable, a set of loosely themed ideas ...
Stack Overflow
Voltaire said: if God did not exist it would be necessary to invent [him], so if Stack Overflow did not exist, it would be necessary to invent it.
Don't worry unduly if you've not heard of Stack Overflow - well unless you're in the business of writing software, in which case tremble mightily. As far as software engineers are concerned, Stack Overflow is the 7th layer of the 5 layer Maslow Hierarchy of Needs
(You've seen the updated 6 layer model with WiFi, right?)
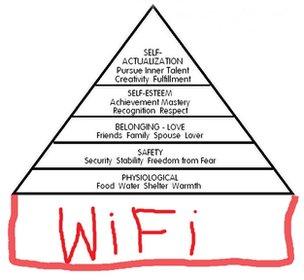{kind=link}
When writing software one often gets stuck, wonders what to do and Stack Overflow is the place to turn to. You find that you're not alone; that people have faced this problem before and that there are 12 different and inconsistent, often wrong, answers to your problem. It makes a massive difference and helps modern engineering productivity hugely.
Trello
Actually I'm not here to talk about Stack Overflow, I want to mention Joel Spolsky. As well as being the co-creator of Stack Overflow he also is responsible for Trello. "Drop the lengthy email threads, out-of-date spreadsheets, no-longer-so-sticky notes, and clunky software for managing your projects. Trello lets you see everything about your project in a single glance."
Not using Trello for organising your company? Consider it. It's not for geeks, it's for real people. Read Joel about the success story behind this technology start-up and in particular take note of his discussion of investors in Trello.
The Joel Test
Trello isn't what I want to talk about either, you can check it out for yourself. What I'm here to talk about and what I've finally got round to mentioning is The Joel Test: 12 Steps to Better Code - which is a "highly irresponsible, sloppy test to rate the quality of a software team".
It was written in 2000. A really, really long time ago, and in part it is showing signs of its age. Have a look at it and adapt it to your circumstances. If you're not writing code yourself, think about it as a source of questions for people who write software for you, or who want to write software for you.
Jo
Sunday 5 April 2015
FoundationDB: A tale to envy with a sting in its tail
I've been watching FoundationDB for a while now, they've been very good at promoting themselves and have had a clear story.
Fast, scalable, resilient ... and best of all, combining the merits of both SQL and NoSQL, you know, like Hovis.
Having raised USD 22M in two rounds, they have been bought by Apple for an undisclosed sum.
Yay!
Here's the sting in the tail.
FoundationDB had in parts been open source. Here's the Git repo now: "This organization has no public repositories."
Not only that but all (including paid) downloads have been removed from the site. This is incredibly bad news for those dependent on it, given the likelihood that they'll need to move to something else.
Even if they have a properly structured interface to their persistence (meaning that code changes are minimised), the fact that the data model is likely to be somewhat or wildly different to what it is in FoundationDB means the data migration is likely to be anything from a nuisance to extremely painful.
There are several lessons one can draw from this.
- Make sure your deployment stack is not a stove pipe and that pieces can be swapped in and out of it.
- Another way of saying that is - as far as you can minimise your hard dependencies (build to standards and abstractions)
- Be boring, don't reach for the newest shiniest things
- Check your licenses. Not only are you not necessarily free to use open source stuff for anything you like, you don't necessarily have any guarantee of ongoing access.
Jo
More Reading
Business Insider: Why Apple bought FoundationDB
TechCrunch: Apple Acquires FoundationDB
Friday 3 April 2015
Google Ranking Algorithm Changes 21 April
For those interested in SEO (and who isn't) please see the this article in SearchEngineWatch. In the past Google has adjusted its algorithm on a periodic basis which has caused some surprise and dismay among some companies when they find themselves suddenly relegated.
The subject of Mobile Friendliness is, unfortunately, rather detailed. Please be aware that "being responsive" and "being mobile friendly" are not the same thing. Some studies claim to show that responsive sites actually contribute to a poorer user experience ... others show the opposite.
For the sake of pure pragmatism and for those less interested in the ins and outs of this discussion, do make sure to follow the links in the article linked above to Google's mobile friendly test.
But also please be aware that sites that would benefit from better mobile optimisation seem to pass this test. If your site varies its layout but doesn't adjust what gets sent to the device you may well be sending things to the mobile user that have unnecessary and undesirable cost and performance implications. If you're interested in improving user experience rather than just checking the SEO box, please also look at Google's PageSpeed.
Also check out the Chrome Developer tools which simulate your site experience on various screen sizes and under various typical network conditions (3G etc.) - hamburger icon | More tools | Developer tools | phone icon - in your Chrome browser.
Jo
Recent news on responsiveness:
The BBC attracted quite a lot of criticism for its recent "move to responsive".
The following is a relatively-speaking polite debate on the topic between religious adherents of both sides of the argument, from the extraordinary Bruce Lawson.
For those with a deeper level of interest in Web technology: among the comments on the above from the great and the good of the Web world please note in particular that of Andrew Betts of the FT. You may or may not remember that the FT famously eschewed an app-based approach in favour of Web only. They know a thing or two about this topic.
Subscribe to:
Posts (Atom)